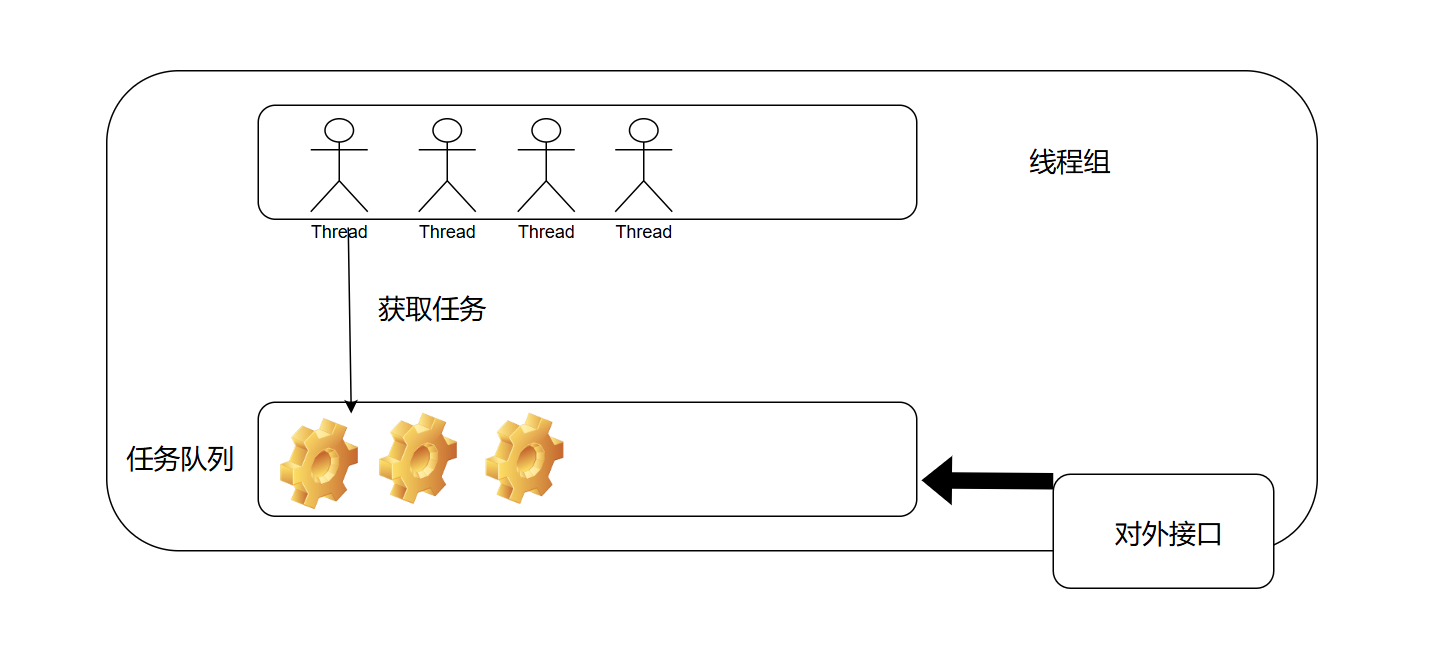
线程池 (Thread Pool) 的基本概念是,在应用程序启动时创建一定数量的线程,并将它们保存在线程池中。当需要执行任务时,从线程池中获取一个空闲的线程,将任务分配给该线程执行。当任务执行完毕后,线程将返回到线程池,可以被其他任务复用。
在处理某些性能受限的任务时,我们通常会创建新线程来处理该任务,以防止进程被阻塞。这样可以一定程度上提高程序的运行性能;然而,这样的处理方式也存在一个问题:频繁创建并销毁进程也是一个对性能要求较高的操作。线程池就是在这个方面进行了性能优化:我们将已经完成了既定任务的线程保留下来,然后使其直接承接新的任务继续运行。如此一来,处理两个任务时,从原来的 两次线程创建两次线程销毁 变成了 一次创建一次销毁 。在任务数目庞大时,这样的性能开销差异会更大。
在着手实现线程池之前,我们需要了解一个线程池需要由什么构成。首先,我们当然需要 一批线程 ,它们是处理任务的主要成员,就好比工厂中的工人一样。此外,我们还需要一个 任务队列 :程序将需要完成的任务放入此队列中,而后不再关心这些任务的状态;当线程池中有线程处于空闲状态时,从任务队列中取出一个任务开始执行。最后,我们需要 一组接口 ,使得用户可以无需关注线程池的实现细节,而使用简单的接口来提交任务。线程池中任务调度无需暴露给用户,这也是一种面向对象的思想。
本质上,线程池的组成部分是相对比较简单的。下面的示意图也说明了它们之间的关系。
首先,我们需要导入pthread库,该库是C++支持多线程的标准库。在本文中,我们主要使用pthread_create()进行线程创建。
上面说到过,线程池中需要存在一批线程不断接受任务队列中的任务进行执行。因此,我们需要创建一个用于维护线程状态的结构体TP_WORKER来储存这些信息。我们将该结构体定义如下,相关解释也一并包含在代码中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct TP_WORKER { pthread_t p; ThreadPool* pool; bool is_running; bool terminate; TP_WORKER* prev; TP_WORKER* next; TP_WORKER (){} TP_WORKER (TP_WORKER* p, TP_WORKER* n, ThreadPool* po) { prev = p; next = n; pool = po; } };
在我看来,我们也可以使用一个vector数组来存储线程向量。在代码实现上,或许会稍微简单些;但在此笔者选择使用链表的原因在于其可以很方便地离开链表,而vector数组中删除中间元素会产生大量的元素移动,造成性能消耗。
首先,我们同样需要一个结构体来描述一个任务。简单来说,一个任务就是 一个带有实参的函数 。在C++中,我们可以通过声明函数指针的方式来获取函数对象,通过声明一个指针来获得函数的实参。然而,在声明函数指针时,我们需要对该指针匹配的函数的返回值和形参列表做出声明。例如我们声明如下的函数指针func:
则该函数指针只能匹配具有两个int类形参,并且返回值为void的函数。这显然会带来一个问题, 我们无法预先知道待处理的任务的函数形式! 这是,我们可以选择一个较为取巧的方式,我们指定函数形式为:
这样,我们对该函数传参时,可以将所有实参包装成一个结构体实例,并传入结构体实例的指针。例如,我们对函数进行如下改写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void printEquation (int a, int b) std::cout << a << " + " << b << " = " << a + b << std::endl; return ; } struct EquationData { int _a, _b; EquationData (int a, int b): _a(a), _b(b){} }; void * printEquation (void * params) EquationData* data = (EquationData*)params; std::cout << data->_a << " + " << data->_b << " = " << data->_a + data->_b << std::endl; return nullptr ; }
这样的做法能够使得所有函数都可以写成void* (*)(void *)的类型。由此,我们就能很简单地构造出描述任务的结构体TP_JOB了:
1 2 3 4 struct TP_JOB { void * (*func)(void *); void * params; };
在线程池类中,需要一些变量来存储线程池的相关信息,如下列出了这些变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class ThreadPool {private : struct TP_CONFIG { int _max_job_cnt; int _cur_thread_cnt = 0 ; }; TP_WORKER* _tp_worker_list; pthread_mutex_t _tp_worker_list_mutex; queue<TP_JOB> _tp_job_queue; pthread_mutex_t _tp_job_queue_mutex; TP_CONFIG _tp_config;
_max_job_cnt表示了线程池的任务队列所能容纳的最多任务数量防止任务堆叠;_cur_thread_cnt储存目前存活的线程数目;_tp_worker_list是线程链表的链表头;_tp_job_queue是任务队列。
上述变量中,_tp_worker_list和_tp_job_queue属于 临界资源 。并发编程中,由于读写变量不是原子操作(由多条CPU指令完成),因此无法防止线程A读出写回过程中线程B不会读出该值,从而导致不一致问题。会被这种情况影响的数据被称为 临界资源 。为了防止不一致的问题,我们引入了读写锁_tp_worker_list_mutex和_tp_job_queue_mutex,在读出前尝试获取该锁,在写回后释放锁来防止不一致问题的产生。
创建线程的函数原型为:
1 int pthread_create (pthread_t * restrict tidp,const pthread_attr_t * restrict_attr,void * (*start_rtn)(void *),void *restrict arg)
tidp就是指向我们在TP_WORKER中的pthread_t p字段的指针,表示线程号;restrict_attr区分线程的不同属性,一般来说我们直接设为nullptr即可;start_rtn是一个函数指针,也就是我们本节所讨论的 回调函数 ,这是新创建的线程的运行入口点;arg是一个参数指针,作为start_rtn的参数。
在线程池的实现中,我们会使用到上述的方法。接下来,我们实现函数ThreadPool::create_thread(),该函数能够为线程池创建一个新的线程使得其能够完成接取任务、执行任务的工作。
我们在上面提到过,TP_WORKER是用于管理线程状态的类,因此,在创建线程之前,我们需要初始化一个TP_WORKER实例,同时对该实例的成员变量进行初始化,并将新的worker实例加入线程链表中,代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 bool create_thread () TP_WORKER* worker = new TP_WORKER (); worker->pool = this ; worker->terminate = false ; worker->is_running = false ; worker->next = this ->_tp_worker_list->next; if (this ->_tp_worker_list->next) this ->_tp_worker_list->next->prev = worker; worker->prev = this ->_tp_worker_list; this ->_tp_worker_list->next = worker; this ->_tp_config._cur_thread_cnt += 1 ; int ret = pthread_create (&worker->p, nullptr , &_thread_Callback, worker); return true ; }
上述代码中主要完成了三件事:1、新建一个TP_WORKER的实例worker,并进行初始化工作;2、将其加入链表之中;3、使用pthread_create()创建了新的线程,并交给worker进行托管。
值得一提的是,这里使用的线程链表为 双向链表 , 并且引入了哨兵节点(即_tp_worker_list指向的TP_WORKER实例不具备任何意义)。这种做法只是简化了链表操作期间的边界条件判断问题,具体解释可见这篇文章 。
之后,我们着重考虑ThreadPool::_thread_Callback()函数的实现,其作为新建线程的入口点。首先,由于pthread_create()参数限制,该函数的原型必须是void* (*)(void *)。然而,我们考虑这样的问题:该函数作为类的成员函数,我们直接声明为如下形式是不可以的:
1 void * _thread_Callback(void * pvoid){}
具体原因在于:在C++中,类的非静态成员函数会有一个隐藏的this指针指向类的具体实例,以便于进行方法调用时能够准确的操作我们希望操作的类实例。因此,上述函数声明实际声明的是如下的函数:
1 void * _thread_Callback(ThreadPool* this , void * pvoid){}
这就会产生编译错误了。因此,正确的函数声明应该为:
1 static void * _thread_Callback(void * pvoid){}
函数参数pvoid应传入我们为该线程创建的TP_WORKER实例指针,即worker,以便于在运行过程中能够读取自身状态参数。那么接下来的操作逻辑就比较简单了,用伪代码表示为如下形式:
1 2 3 4 5 6 7 8 9 while(true){ if 自身接取了任务: 完成之 else: if 自己的 terminate 设置为 true: 销毁自身,释放空间 else: 尝试获取一个新的任务,若不存在,则不做任何操作 }
使用C++实现之,则代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static void * _thread_Callback(void * pvoid) { TP_WORKER* worker = (TP_WORKER*) pvoid; worker->is_running = false ; TP_JOB job; ThreadPool* pool = worker->pool; while (true ) { if (worker->terminate && !worker->is_running) { pthread_mutex_lock (&(pool->_tp_worker_list_mutex)); worker->prev->next = worker->next; if (worker->next) { worker->next->prev = worker->prev; } pthread_mutex_unlock (&(pool->_tp_worker_list_mutex)); delete worker; pthread_exit (nullptr ); } if (!worker->is_running) { pthread_mutex_lock (&(pool->_tp_job_queue_mutex)); if (!pool->_tp_job_queue.empty ()) { job = (pool->_tp_job_queue).front (); pool->_tp_job_queue.pop (); worker->is_running = true ; } pthread_mutex_unlock (&(pool->_tp_job_queue_mutex)); }else { void * res = job.func (job.params); printRes ((int )worker->p, *(int *)res); worker->is_running = false ; } }
完整的代码如下,可供读者参考借鉴:
线程池的简单C++实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 #include <pthread.h> #include <iostream> #include <queue> #include <vector> using namespace std;pthread_mutex_t print_mutex = PTHREAD_MUTEX_INITIALIZER;void printRes (int no, int res) pthread_mutex_lock (&print_mutex); cout << "Answer: " << res << " Computed by thread: " << no << endl; pthread_mutex_unlock (&print_mutex); } class ThreadPool {private : struct TP_WORKER { pthread_t p; ThreadPool* pool; bool is_running; bool terminate; TP_WORKER* prev; TP_WORKER* next; TP_WORKER (){} TP_WORKER (TP_WORKER* p, TP_WORKER* n, ThreadPool* po) { prev = p; next = n; pool = po; } }; struct TP_JOB { void * (*func)(void *); void * params; }; struct TP_CONFIG { int _max_job_cnt; int _cur_thread_cnt = 0 ; }; TP_WORKER* _tp_worker_list; pthread_mutex_t _tp_worker_list_mutex; queue<TP_JOB> _tp_job_queue; pthread_mutex_t _tp_job_queue_mutex; TP_CONFIG _tp_config; static void * _thread_Callback(void * pvoid) { TP_WORKER* worker = (TP_WORKER*) pvoid; worker->is_running = false ; TP_JOB job; ThreadPool* pool = worker->pool; while (true ) { if (worker->terminate && !worker->is_running) { pthread_mutex_lock (&(pool->_tp_worker_list_mutex)); worker->prev->next = worker->next; if (worker->next) { worker->next->prev = worker->prev; } pthread_mutex_unlock (&(pool->_tp_worker_list_mutex)); delete worker; pthread_exit (nullptr ); } if (!worker->is_running) { pthread_mutex_lock (&(pool->_tp_job_queue_mutex)); if (!pool->_tp_job_queue.empty ()) { job = (pool->_tp_job_queue).front (); pool->_tp_job_queue.pop (); worker->is_running = true ; } pthread_mutex_unlock (&(pool->_tp_job_queue_mutex)); }else { void * res = job.func (job.params); printRes ((int )worker->p, *(int *)res); worker->is_running = false ; } } } public : ThreadPool (int threads_cnt, int max_job_cnt) { this ->_tp_job_queue_mutex = PTHREAD_MUTEX_INITIALIZER; this ->_tp_worker_list_mutex = PTHREAD_MUTEX_INITIALIZER; this ->_tp_worker_list = new TP_WORKER (nullptr , nullptr , this ); this ->_tp_config._max_job_cnt = max_job_cnt; this ->_tp_config._cur_thread_cnt = 0 ; for (int i=0 ; i<threads_cnt; ++i) { create_thread (); } } ~ThreadPool () { DestroyThreads (this ->_tp_config._cur_thread_cnt); pthread_mutex_lock (&_tp_worker_list_mutex); delete _tp_worker_list; pthread_mutex_unlock (&_tp_worker_list_mutex); } bool create_thread () TP_WORKER* worker = new TP_WORKER (); worker->pool = this ; worker->terminate = false ; worker->is_running = false ; worker->next = this ->_tp_worker_list->next; if (this ->_tp_worker_list->next) this ->_tp_worker_list->next->prev = worker; worker->prev = this ->_tp_worker_list; this ->_tp_worker_list->next = worker; this ->_tp_config._cur_thread_cnt += 1 ; int ret = pthread_create (&worker->p, nullptr , &_thread_Callback, worker); return true ; } bool push_job (void * (*func)(void *), void * params) bool state = false ; pthread_mutex_lock (&_tp_job_queue_mutex); if (_tp_job_queue.size () < this ->_tp_config._max_job_cnt) { _tp_job_queue.push (TP_JOB (func, params)); state = true ; } pthread_mutex_unlock (&_tp_job_queue_mutex); return state; } int getThreadCnt () return this ->_tp_config._cur_thread_cnt; } int DestroyThreads (int number) pthread_mutex_lock (&_tp_worker_list_mutex); TP_WORKER* worker = _tp_worker_list->next; while (number > 0 && worker) { worker->terminate = true ; number --; this ->_tp_config._cur_thread_cnt --; worker = worker->next; } pthread_mutex_unlock (&_tp_worker_list_mutex); return getThreadCnt (); } };
如同哈希表一样:较小的使用率会导致哈希表的绝大多数空间被浪费;较高的使用率则会使得哈希碰撞变得更加频繁,导致性能下降;对于线程池而言,也有类似的困难:任务数目远大于线程数目的线程池无法及时处理任务队列的任务导致任务队列中充斥大量任务;而线程数目远大于任务数目则会导致大多数线程处于空闲状态,浪费系统资源。因此,动态调整线程池中线程的数目是一个值得优化的点(虽然上述代码中尚未实现,但已经封装了创建和删除线程的函数,读者可以一试之)。
在特定使用情境下,线程池也可作出不同程度的优化:例如,在Java中设定了核心线程数,即使当前有线程空闲,也会创建新的线程来执行任务;反之,如果线程池中的线程数目大于核心线程数,则会依据原先设定的生命周期销毁一部分线程,以此来达到所谓的动态平衡。