我们时常希望博客的友链界面能够对不同的友链分组;stellar的动态友链功能又十分强大,但所有导出的数据都会写入一个文件。这篇文章记录对动态友链生成仓库的改造,使之能够进行友链分类。
11月15日更新
最新版本的动态友联已经支持输出到自定义文件,因此读者继续参考本文时请注意文章的时效性。
由于本文对于仓库源码有一定的改动,请先确认你是否确实有这个需求,而后再理性地选择是否魔改。
废话我就不多说了,我们直接开始。
fork动态友链抓取仓库
首先,你需要fork动态友链抓取仓库,链接如下:
根据README内容完成配置。这里我就不多赘述了,需要保证你的workflow能够正确运行并且output分支能看到输出的data.json文件。
代码修改
在这个魔改中需要修改两部分内容(均处于main分支下):config.yml和generator/main.py。这里先给出两者的文件:
提示
在复制源码前,我建议你看看我都改了什么。这有助于你对代码有宏观的把握,也对程序中可能出现的问题有解决想法。
config.yml
config.yml1
2
3
4
5
6
7
8
9
10
11
12
13
| # 网络请求设置
request:
timeout: 10 # 超时设置
ssl: false # ssl设置
# 要抓取的 issues 配置
issues:
repo: felixchen0707/friendLink_api # 仓库持有者/仓库名
label: active # 筛选具有 active 标签的 issue ,取消此项则会提取所有 open 状态的 issue
+ className:
+ - 'ordinary'
+ - 'top'
sort: updated-desc # 排序,按最近更新,取消此项则按创建时间排序
|
config.yml1
2
3
4
5
6
7
8
9
10
11
12
13
|
request:
timeout: 10
ssl: false
issues:
repo: felixchen0707/friendLink_api
label: active
className:
- 'ordinary'
- 'top'
sort: updated-desc
|
generator/main.py
generator/main.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| # -*- coding: utf-8 -*-
# author: https://github.com/Zfour
from bs4 import BeautifulSoup
import os
import request
import json
import config
version = 'v2'
outputdir = version # 输出文件结构变化时,更新输出路径版本
- filename = 'data.json'
data_pool = []
+ cfg = config.load()
+ filter = cfg['issues']
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.makedirs(path)
print("create dir:", path)
else:
print("dir exists:", path)
- def github_issuse(data_pool):
+ def github_issuse(data_pool, className):
print('\n')
print('------- github issues start ----------')
+ print('is catching label:' + className)
baselink = 'https://github.com/'
- cfg = config.load()
- filter = cfg['issues']
try:
for number in range(1, 100):
print('page:', number)
url = 'https://github.com/' + filter['repo'] + '/issues?page=' + str(number) + '&q=is%3Aopen'
if filter['label']:
- url = url + '+label%3A' + filter['label']
+ url = url + '+label%3A' + filter['label'] + '+label%3A' + className
if filter['sort']:
url = url + '+sort%3A' + filter['sort']
print('parse:', url)
github = request.get_data(url)
soup = BeautifulSoup(github, 'html.parser')
main_content = soup.find_all('div', {'aria-label': 'Issues'})
linklist = main_content[0].find_all('a', {'class': 'Link--primary'})
if len(linklist) == 0:
print('> end')
break
for item in linklist:
issueslink = baselink + item['href']
issues_page = request.get_data(issueslink)
issues_soup = BeautifulSoup(issues_page, 'html.parser')
try:
issues_linklist = issues_soup.find_all('pre')
source = issues_linklist[0].text
if "{" in source:
source = json.loads(source)
print(source)
data_pool.append(source)
except:
continue
except Exception as e:
- print('> end')
+ print('> end catching label:' + className)
print('------- github issues end ----------')
print('\n')
# 友链规则
+ for className in filter['className']:
+ data_pool.clear()
- github_issuse(data_pool=data_pool)
+ github_issuse(data_pool=data_pool, className=className)
mkdir(outputdir)
- full_path = outputdir + '/' + filename
+ full_path = outputdir + '/' + className + '.json'
with open(full_path, 'w', encoding='utf-8') as file_obj:
data = {
'version': version,
'content': data_pool
}
json.dump(data, file_obj, ensure_ascii=False, indent=2)
|
generator/main.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
from bs4 import BeautifulSoup
import os
import request
import json
import config
version = 'v2'
outputdir = version
data_pool = []
cfg = config.load()
filter = cfg['issues']
def mkdir(path):
folder = os.path.exists(path)
if not folder:
os.makedirs(path)
print("create dir:", path)
else:
print("dir exists:", path)
def github_issuse(data_pool, className):
print('\n')
print('------- github issues start ----------')
print('is catching label:' + className)
baselink = 'https://github.com/'
try:
for number in range(1, 100):
print('page:', number)
url = 'https://github.com/' + filter['repo'] + '/issues?page=' + str(number) + '&q=is%3Aopen'
if filter['label']:
url = url + '+label%3A' + filter['label'] + '+label%3A' + className
if filter['sort']:
url = url + '+sort%3A' + filter['sort']
print('parse:', url)
github = request.get_data(url)
soup = BeautifulSoup(github, 'html.parser')
main_content = soup.find_all('div', {'aria-label': 'Issues'})
linklist = main_content[0].find_all('a', {'class': 'Link--primary'})
if len(linklist) == 0:
print('> end')
break
for item in linklist:
issueslink = baselink + item['href']
issues_page = request.get_data(issueslink)
issues_soup = BeautifulSoup(issues_page, 'html.parser')
try:
issues_linklist = issues_soup.find_all('pre')
source = issues_linklist[0].text
if "{" in source:
source = json.loads(source)
print(source)
data_pool.append(source)
except:
continue
except Exception as e:
print('> end catching label:' + className)
print('------- github issues end ----------')
print('\n')
for className in filter['className']:
data_pool.clear()
github_issuse(data_pool=data_pool, className=className)
mkdir(outputdir)
full_path = outputdir + '/' + className + '.json'
with open(full_path, 'w', encoding='utf-8') as file_obj:
data = {
'version': version,
'content': data_pool
}
json.dump(data, file_obj, ensure_ascii=False, indent=2)
|
如何配置className
在我的构想中,一个网站应该由两部分构成:网站状态和网站分类。前者通过active、404、suspend这类的label进行标记;后者则是你自定义的分类。
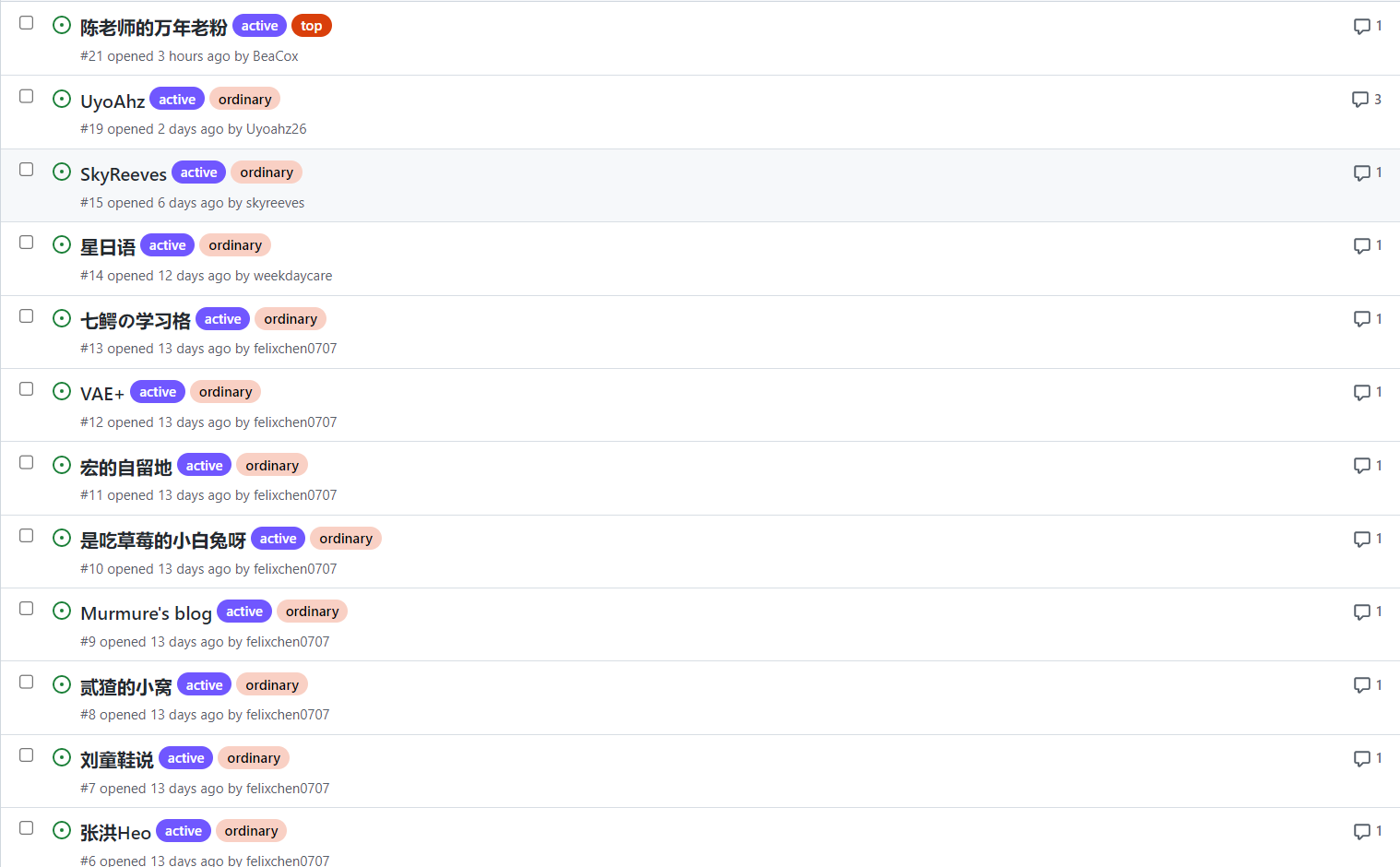
对于你自定义的分类名称,你需要写在config.yml中的className项中,例如我这里用ordinary和top来区分一般友链和置顶友链。经过配置后的className包含的元素会在执行action的时候依次被作为label单独抓取合适的友链,例如下图是我的友链仓库:
其中,标记为active的issue表示允许被抓取,而标记为top和ordinary的issue会在抓取top和ordinary的两批抓取中分别被抓取,来达到对友链分类的效果。
期望的运行结果
被标记为classA的友链将会输出至output分支下v2/classA.json文件中,其他情况类似。由于label的名字与输出文件的名字强相关,这也要求你不要用奇怪的符号作为label的内容。
一些些补充
每个issue对应两个label
由于我使用站点状态和站点分类来分别表示一个网站,因此每一个issue至少都有两个label标记。例如,你的config.yml中配置了:
config.yml
若你仅仅为一个issue打上了ordinary标记而没有加上active标记或者反之,则该issue都不会被读取到。
加快访问速度
由于直接访问github的速度极慢,你可以使用Vercel构建该仓库来达到加速访问的效果。在你的Vercel的面板界面(dashboard)新建项目,导入你的友链数据仓库并点击deploy。由于你的输出内容一般不在main分支但是Vercel却会默认构建main分支,你需要进行以下操作:
点开项目,进入Settings->Git界面,找到Production Branch配置项,将分支名称从main/master改成output。下次向output分支推送时,Vercel就会重新改为部署该分支了。
致谢